Continuing with my previous note here: http://publiclab.org/notes/Sreyanth/06-24-2013/find-closest-match-spectra-from-database-gsoc-project , I would like to let you know the progress of the project, drastic changes from the previous post and most importantly, I would like you to see some working results.
Changes from the previous note.
In the previous note, I have considered the problem as an image matching one and went ahead writing some code to search for candidate matches. Later, it was quite evident that the data is not being used to the fullest and the time taken is arguably high for a real-time system (was taking about 3 seconds).
So, after a series of discussions, I have decided to take the wavelength-intensity data and perform analysis on it. This surprisingly gave good results. The code can be still optimized, but the only thing I would do is to complicate the logic. So, I have made a time-simplicity trade off so that at least some accurate matches can be found - which I call as candidate matches. These need to be ranked appropriately based on some closeness measure.
Are these changes fruitful?
Let me show you some results which we obtained after making the above stated changes in the approach.
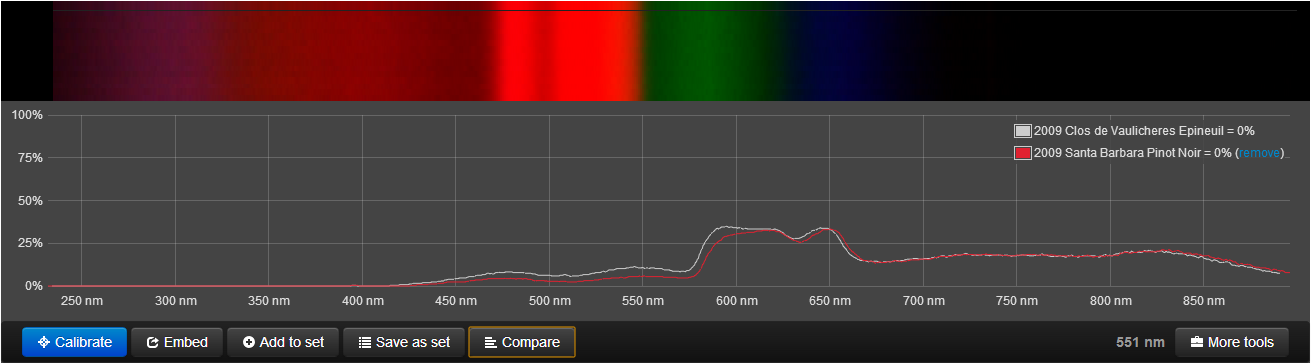
For the spectrum: https://spectralworkbench.org/analyze/spectrum/73 , I have obtained

For the spectrum: https://spectralworkbench.org/analyze/spectrum/410 , I have obtained

For the spectrum: https://spectralworkbench.org/analyze/spectrum/69 , I have obtained

For the spectrum: https://spectralworkbench.org/analyze/spectrum/390 , I have obtained

Larger images of the results here:
http://publiclab.org/system/images/photos/000/000/950/original/match_73.png http://publiclab.org/system/images/photos/000/000/952/original/match_410.png http://publiclab.org/system/images/photos/000/000/949/original/match_69.png http://publiclab.org/system/images/photos/000/000/951/original/match_390.png
{kind=link}
{kind=link}
{kind=link}
{kind=link}
How did we do it?
After deciding to use the wavelength - intensity plots as data for searching instead of 2D imagery, I started exploring how the data in the Spectral Workbench database has been organized.
But, matching each spectrum with every other spectrum in the database is definitely time taking. So, we will have to come up with some algorithm to eliminate notForSureSimilar spectrums. If we are able to eliminate these, then we only have mayBeSimilar spectrums with us -- which I refer to as Candidate Spectrums. Once we have the candidate spectrums, it is Okay to use a 1-1 matching algorithm as it may not take a long time, may be some milli seconds.
So, basically I came up with this approach.

In the above image, the orange line is the spectrum for which the matches are to be searched. So, I define a arbitrary search radius (denoted by 'x') and create a search band around the spectrum. All the spectrums which fall in this search band completely in the 450nm to 650nm (why only this range? See my further explanation) are found. Those will be the candidate spectrums for our further experiments. To make the further processing almost unnecessary, I have repeated the same algo for the RGBA values ('A' being average of R-G-B values) and considered those spectrums which fall in the search band for all these 4 cases (R, G, B, A). Thus the most effective matches are found!
So far so good, any problem? Yes.
Sooner after I came up with this idea in my mind, I realized that the spectral data is not regular as I expected it to be i.e., a spectrum may have some intensity at 300nm whereas someother spectrum need not have it. This is indeed a problem.
So, I have taken random data points from the data which were present in almost all the spectra -- ranging from 450nm to 650nm. This seemed to be working. And... this further facilitated us to exploit the MySQL query directly to and it worked like charm!
What next?
Though the given solution works well, it really looks at the data strictly. very strictly indeed. While capturing the data, there may be some errors crept in (or due to some other reason), in which case the spectrum may be shifted in the X-direction either to the left or right side by a few nm. This needs to be accommodated. Then, need to port the code to Ruby -- so that it integrates well into the SWB. Then, I can directly accommodate the ranking features and interestingness measurement code in Ruby.
This is what I plan to do in the next few weeks until I post my next research note with updates. Please feel free to let me and my mentor, Jeffrey Warren if we can accommodate any further features. As of now, finding a closest match is the main idea. We plan to later extend this to predict the material too. Thanks for all those who gave their valuable insights in the mailing list.
Sreyanth
1 Comments
This is awesome work!
Reply to this comment...
Log in to comment
Login to comment.