Purpose
The purpose of this research note is to share some of the experience and design considerations for the Advanced Search Project. Although the UI will be fairly straightforward and understandable, there are a wide variety of design choices that will need to be made for the underlying "search engine" to support the user interface(s).
During the Community Bonding Period of the Google Summer of Code project, the Advanced Search Project team has been working through the design requirements, technological considerations, and the fundamental goal of supporting Public Lab's community. What follows is a discussion of some of the design choices that are being made, as well as identifying the basic business logic and operational requirements that the team intends to support.
Short- and Long-Term Goals
Fig. 1 shows a conceptual layout for a fully integrated indexing- and search- system that would be able to handle search functionality across any current and future Public Lab sites for the foreseeable future. This is fairly ambitious, and is included only to show how a large-scale system could be designed.

Fig. 1 Long Term Design for full index-and-search system within Public Lab
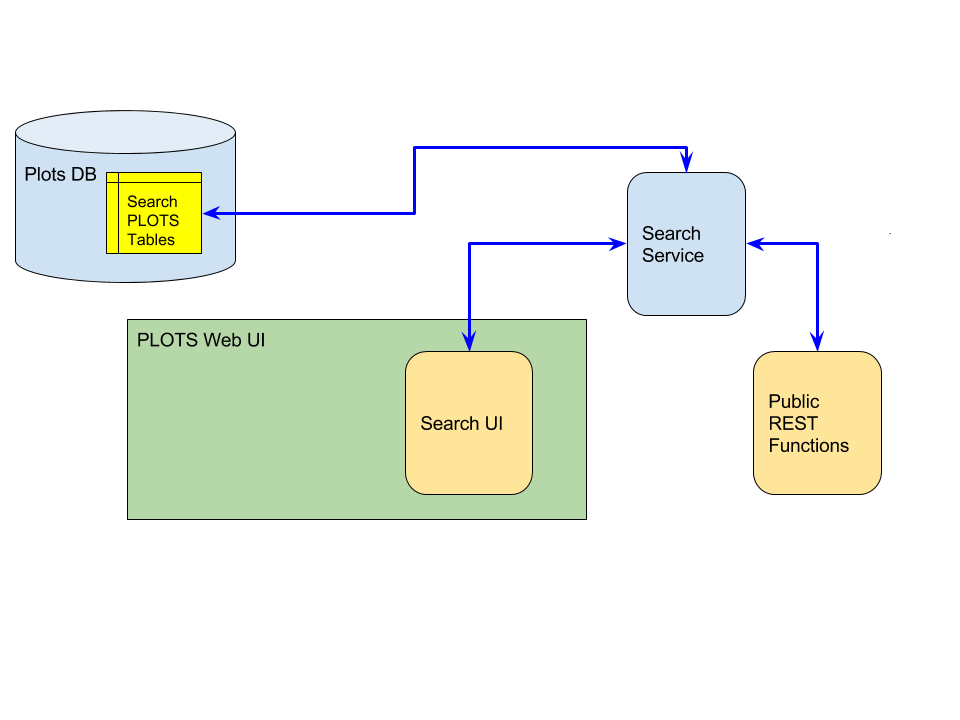
Because of the limited time available for the Google Summer of Code (GSoC) project, as well as the desire to make small, modular changes to the plots2 code at each step, the formal goal of the Advanced Search Project is to implement the system in Fig. 2.

Fig. 2 Short-term goal for the Advanced Search Project
Note that, when completed, the search engine and services of the Advanced Search project should lay the groundwork for the larger system in Fig. 1.
Starting Points in Web Service Design
When designing a web service, it is often difficult to figure out precisely where to begin. This is often because a web service of any form (RESTful, SOAP, or even strict machine-to-machine formats) represents an intersection of business logic, persistence (database) calls, and a wide variety of potential client applications. A wary developer will spend a lot of time over-thinking every possible use-case and getting very little coding done; although careful design is important, this can be bad for a time-sensitive project.
Alternatively, an over-anxious developer will start writing code for the most obvious or immediate use-cases to “get the job done”. However, this leads to a lot of refactoring, repeated code, and ever-deepening testing issues as more requirements, use-cases, and language- or client-specific restrictions are encountered. In the end, a lot of technical debt is built up because of early implementations that have to be reworked.
In order to navigate these extremes, an approach that has served me well in the past is to start with the highest-level view of the interactions and most likely components. That is the approach that the rest of this document will take, and from there we will try to build out a basic set of concepts. The actual entities will be written out in a separate document.
The “90% Solution” for Technologies
In the Advanced Search Project, the technologies involved are actually pretty well defined, and make a good starting point:
- Ruby as the RESTful service language
- Ruby MVC web applications (plots2)
- MySQL database backend
- Web browser client
- Javascript/AJAX (JQuery)
At some point it is possible that other clients may be added in the future (Android/iOS, desktop apps, etc), but at this point, this list is all the foreseeable technology that will compose the search system and search clients.
Basic Operational Requirements
It may seem to be overkill, but it’s worth taking the time to define, precisely, what the service is required to do when called. This doesn’t have to be a rigorous definition of operations and results, but it often exposes assumptions, conflicts, and behaviors that haven’t been explicitly stated. The listing below is a good place to start:
- Basic Search
- Requirement Find pages/notes/etc via search box or page
- Software Search the database for matching items
- Returns List of links to these notes/pages/etc
- Typeahead
- Requirement Present users with a list of matching values as they type entries in search boxes
- Software Search the database for matching titles, profiles, tags, etc
- Returns List of matching terms/values that match the typeahead entry
- Search according to tags
- Requirement Provide a search capability based on assigned tags
- Software Search the database for matching entries according to assigned tags
- Returns List of links to these matching notes/pages/etc
- Search profiles
- Requirement Search profiles for matching information
- Software Search the database for matching profiles
- Returns List of links to the appropriate profiles
- Search new Q&A system (when it is finished)
- Requirement Provide search functionality for new Q&A system.
- Software Search the database for matching Q&A entries
- Returns List of links to these matching Q&A pages
- Additional Search Filtering/Sorting
- Requirement Restrict searches via additional criteria (ratings, keywords, review process, etc) for any/all operations, sort appropriately
- Software Filter search results further according to additional criteria
- Returns Sorted and filtered list of links to matching profiles/pages/etc.
- Search and return existing tags (similar to typeahead functionality #2)
- Requirement Search existing tags that match user-entered values
- Software Match user entries with existing tags
- Returns Return list of matching tags
The Returns entry for each requirement in the listing starts to show some interesting patterns. First, there are two types of return values that are needed: A collection of links to various web documents (Operations 1 and 3-5), and a collection of matching terms/values/text entries (Operations 2 and 7). Operation #6 is an input requirement--applying customization to the return results.
Returning a Collection of Links
Although it may seem obvious, the primary function of the search engine is to return a list of available documents that match a query. This list of matching documents is presented to the user, who can then choose to either a) perform another search, or b) use a link to go to a chosen document.
(The term "document" is intended to denote any coherent data to be located by a link, be it a research note, a user profile, a data set, or a map image. This term is fairly standard and will be used often throughout the Advanced Search Project.)
However, presenting a list of raw links, in and of themselves, provides little value. For example, the URL for this document in Google Docs is https://docs.google.com/document/d/1St95VE7wGT8yYbMbC2DMa2Vwhg8iNTP5b_aaszLeczo/edit# and provides very little information to a human user. In order to allow the user to make reasonable choice amongst several options, other data has to be provided. A suggested list of values and property names follows:
- docUrl: The URL of the matching item.
- docTitle: A title/name/header, if available, that can be presented as the link text.
- docType: An indication of the general type (notes, research, review, image, dataset, etc) the docUrl retrieves.
- docTags: List of the tag values associated with the search. This could allow the user to refine the search more quickly, especially if nomenclature or terminology is an issue.
- docSummary: For a text document (note, research, review, or question) either an abstract, first paragraph, or associated key words. For an image or data set, it could be a summary of the size or complexity of the item
- srchRelevance: A score value for the relevance to the search item. Including this allows client-side custom sorting, if desired
- srchTerms: A collection of keywords (suggested, computed, or pre-calculated) that have the highest probability of bring back this document.
While this list is not exhaustive, a few things should be noted. First, due to the technology involved (Javascript, Ruby, Web browsers), terms like “document”, “url”, “title”, “rel”, and others are reserved keywords in one or more components. In order to minimize bugs related to using reserved words, a general approach is to prepend “doc” to items that relate to the document, and “srch” to properties that relate to the search functions.
Second, the list of returned values is influenced by the final usage of the value: Whether the client is a Ruby page or a JQuery function, there needs to be enough information returned to construct a presentable choice for the user.
Finally, it should be noted that the internal functioning of the search can also provide information. In this example, “srchRelevance” can give the user an idea of how closely the result matched the request, and can choose to modify the search accordingly. Other possible items include closely-associated search terms (additional or extracted tags), recent frequency or rank of the item in searches over a period of days, or other metadata.
Returning a Collection of Text Values
The other return type is a list of matching or suggested text values. These can be used in a couple of situations. One is the current typeahead function the plots2 SearchController--providing a list of matching titles, profiles, etc that contain the previously typed letters.
Another common usage is when an author is tagging a note or research article. Rather than have multiple (mis)spellings of tag values in the database, it’s possible to present a list of matching tags that already exist. (The user can explicitly add a new tag, or they can select one of the existing ones). This cleans up the tagging system, as well as leads to more efficient searches (fewer overall entries to be processed).
Note that a list of tag values is very similar to the “srchTerms” property for the document result class above--in fact, it may be worth considering this as an underlying class. An example of this would be srchTerms = [“tag1”,”tag2”,...], and part of the "SearchDocument" class would have an instance of the “srchTerms” class as a value.
As with the previous document class, it may be desirable to add other metadata to the overall class, such as document counts, relevancy, frequency, etc. This is probably a point for future discussion, as a simple list of text will suffice for the first round of implementation.
Future Expansion and Modifications
The format for the return values has already settled upon as JSON. This is in perfect alignment with both RESTful services, as a general practice, and with the current plots2 software. However, it is worth going over the implications of this choice when considering the search engine classes.
First, there are actually two potential clients for the search engine: Javascript -> Search Engine calls and Ruby -> Search Engine calls.
Javascript Clients
The Javascript calls to the search engine are basically AJAX calls to the exposed RESTful endpoints, and the results are returned as JSON. The received Javascript will have to parse the results accordingly, format them according to the intended Document Object Model usage, and place them in the page. This means that a library of search functions will have to be built (the actual “search client” in this discussion).
For the Javascript client, expansion is fairly easy: JSON is evaluated as an Object, with a list of properties (properties whose values are either primitives or other objects). If an additional value is added to the return object, Javascript that would exist in “search.js” (as an example) will typically ignore the new property until specifically called. If a property is significantly altered (changed from a primitive to an array or an object), then the corresponding functions in “search.js” would have to be modified, but only those that deal directly with the altered property. This makes maintenance, testing, and added functionality relatively simple.
Ruby Clients
For the first implementation, the search engine code and services will be written inside the plots2 codebase. The Ruby -> Search Engine calls are internal calls to the Search Engine classes, and the results are passed to page templates accordingly. The final page is then returned to the client browser. This allows for direct access of the search functionality whenever necessary.
Links and Tutorials Relevant to Search Functions
The following is a very brief list of tutorials, research papers, and examples of search functionality and usage. Not every link is immediately relevant to this project, but reading through them should give a developer an idea of the computational issues and possibilities that relate to creating search functions.
Live Search And Ajax
These are tutorials on implementing client-side “live search” functionality. While only some of them actually perform RESTful calls, they are good examples of processing the search results on both the server and client side. In most cases, it is fairly straightforward to replace the DOM-tree search with an AJAX call to a RESTful endpoint.
- Querying Wikipedia using AJAX live search
- This one places formatting in the returned results, which is generally a less-than-optimal practice for a generic search web service: W3 Schools Live search using PHP and Ajax
- Live Search and Client Sorting!
- Example with some hints/tricks that aren't obvious.
Academic Papers on Search/Indexing Schemes
- The Anatomy of a Large-Scale Hypertextual Web Search Engine
- A Task-Specific Query and Document Representation for Medical Records Search <=As an example of a specialized search system
- Integrating Document Usage with Document Index in Competitive Intelligence Process <= Calculating relevance in a search
- Data Structure Lower Bounds for Document Indexing Problems <= Math-heavy, but gives a good overview of the restrictions on fast/efficient searches
- AN EMPIRICAL STUDY OF CONFUSION MODELING IN KEYWORD SEARCH FOR LOW RESOURCE LANGUAGES <= From IBM
- Sentiment Analyzer: Extracting Sentiments about a Given Topic using Natural Language Processing Techniques <= Auto-analyzing a document (indexing)--one of the authors was my machine learning professor a few years ago.
- Mining Knowledge from Text Using Information Extraction <= Auto-analyzing a document (indexing)--same author relationship as above.
0 Comments
Login to comment.