
About Me
Name : Barun Acharya
Github : https://github.com/daemon1024
Project Title : Geographic Features Refinements
Gitter : daemon1024
Affiliation : Jaypee Institute of Information Technology, India
Location : Noida, India
Student year: Sophomore (second-year student)
Field of study: Computer Science and Engineering, B.Tech.
Portfolio : https://daemon1024.github.io/
Project Description
Abstract/Summary (<20 Words)
Smoothen, expand and refine the various geographical features under Public Lab's website. This includes standardizing, adding new leaflet environmental layers, increasing content on https://publiclab.org/map and various other refinements.
Problems
Standardize "Spreadsheet to Layer"
We have an awesome utility to add a leaflet environmental layer using data sourced from a spreadsheet, more details at https://github.com/publiclab/leaflet-environmental-layers#spreadsheet-based-layers. But currently it's not feasible for non programmers to use this utility or how to source the data for the layer to be based upon.
Workflow

The above workflow doesn't need a server dependency as it is automated using GitHub API and actions, and in case of any failure it still provides a manual alternative.
The intended workflow would start with volunteers submitting the form, which automatically opens up an issue, which in turn triggers the GitHub action, the script runs in the action environment and finally generates a pull request with the new layer.
The proposed workflow has fallback for each and every step, in case any step has a failure there will be a provision to complete it manually.
In case every automation fails, the fallback and most basic workflow is providing the volunteer with instructions to open up an issue. Once a public lab contributor picks it up, they have to manually run the script to generate the new layer and make a pull request linking it back to the issue.
I understand that the primary audience might not all be developers and will try to maintain a smooth workflow for them while detailing out each and every fallbacks and progress while making the whole process extremely accessible.
Details about spreadsheet2layer.js:
- Provide an abstraction for https://github.com/publiclab/leaflet-environmental-layers/blob/master/src/util/googleSpreadsheetLayer.js
- Has minimum required user inputs
- Auto Generate tests for the generated layer
- An extremely simplified function code to generate the layers
Some additional points to note:
- We can provide "Open Gitpod to try out new layer" option in the generated pull request.
- Providing an independent file/code which can be included/copied over to anyone's codebase so as to include the generated layer. We can see some examples at https://github.com/publiclab/leaflet-environmental-layers#adding-layers-individually but they still require LEL dependency. We can refactor some of the internal dependency so as anyone can include them.

- We can generate sample previews using these independent components and deploy them to static pages using github pages or alternatives.
Add and refine environmental layers as part of the Leaflet Environmental Layers library
Since we would have a new standardized process to add spreadsheet based layers, it will open up ample opportunity to add various layers.
Also there are many issues open regarding layer requests, broken layers or need for optimizations publiclab/leaflet-environmental-layers/issues. I will try to address them.
Increase amount of content shown per page-view at /map
Currently the content on https://publiclab.org/map on initial load shows very few users/pages and gradually increases.
The current possible solution includes developing a microservice which scrapes the Public Lab API. This micro-service intends to replace the current direct API access.
Details about the microservice:
- Cache data from API to reduce server load?
- Provide data more in line with how we want to display content
- Provide a bbox-queryable GeoJSON service
- Ensuring the content is ranked by some filters like recency, views, comments, likes etc. . . as well as adding an option to provide custom filters.
The current API at /api/nearbyPeople returns data in the form of
{
"items": [
{
"doc_id",
"doc_type",
"doc_url",
"doc_title",
"latitude": "42",
"longitude": "-71",
"blurred": true,
.
.
},
Since the microservice would be a GeoJSON service, the proposed form of data returned would be:
{
"type": "PlacesCollection",
"places": [
{
"type": "place",
"geometry": {
"type": "Point",
"coordinates": [102.0, 0.5]
},
"properties": {
"blurred": "",
"id":"",
"name":,
data
.
.
.
}
},
],
"type": "PeopleCollection",
"People": [
{
"type": "Person",
"geometry": {
"type": "Point",
"coordinates": [102.0, 0.5]
},
"properties": {
"profile": "",
"id":"",
"name":,
data
.
.
.
}
},
]
}
Since GeoJSON would be a standardized format of data it would help integrate PL data with other applications as well.
For legacy support, we can choose to provide them both and only respond with GeoJSON when the API request type is application/geo+json.
Improving Load Times
We are currently loading individual nodes while monitoring loads. I propose to pre cluster various nodes based on zoom levels and we dynamically create requests based on the current bounding box. The simplest way is to use a plugin such as Marker Clusterer. Clusterer helps the rendering on the client side greatly as it means the client computer doesn't have to draw hundreds/thousands of points, it just draws 10-40.
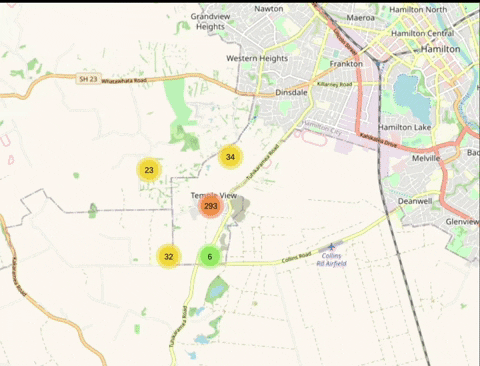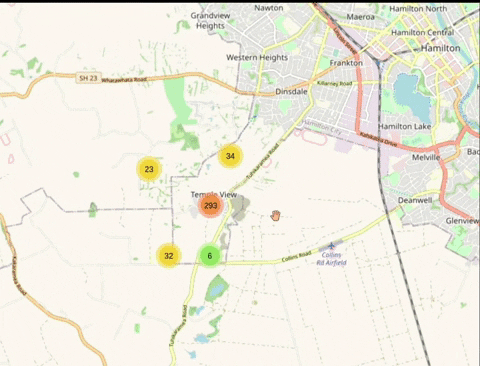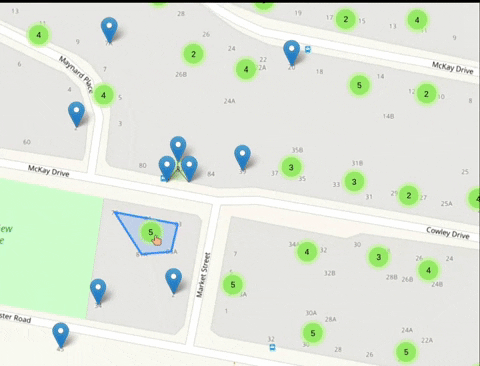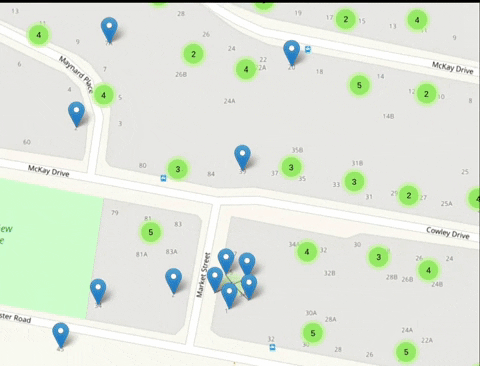
Ensure empty people grid squares don't generate pop-ups and ensuring grid squares with blurred locations are tinted

Currently every empty grid square generates this pop-up. This pop-up should only be generated on grid squares which are actually blurred in line with https://github.com/publiclab/leaflet-blurred-location and these grid squares should be tinted and should be visibly different from other grid elements.
Timeline
| Time period | Tasks |
|---|---|
| Community Bonding Period | |
| Coding Period Starts | |
| Week 1 (June 7, 2021 - June 14, 2021) | |
| Week 2 (June 14, 2021 - June 21, 2021) | |
| Week 3 (June 21, 2021 - June 28, 2021) | |
| Week 4 (June 28, 2021 - July 5, 2021) | |
| Week 5 (July 5, 2021 - July 12, 2021) | |
| Week 6 (July 12, 2021 - July 19, 2021) Evaluations (July 12, 2021 - July 16, 2021) |
/map |
| Week 7 (July 19, 2021 - July 26, 2021) | |
| Week 8 (July 26, 2021 - August 2, 2021) | |
| Week 9 (August 2, 2021 - August 9, 2021) | |
| Week 10 (August 9, 2021 - August 16, 2021) | |
| Week 11 (August 16, 2021 - August 23, 2021) | Code Submission and Final Evaluations |
I have only listed down the potential priority and focus tasks for each week in the above timeline, In addition to that my work in each week would be a blend of the following :
- Breaking down issues into smaller modular tasks
- Interacting and getting feedback from mentors
- Team meetings
- Helping out other contributors
Testing
Testing is a very important aspect of software development. It helps in more accurate, consistent and reliable results. I plan to add all unit, functional, integration and system tests, since we need them all for all 'units' to work cohesively. I will be adding unit tests after completing each unit/functions. For integration tests, I prefer the top-down approach and testing each unit integration step by step and expanding. Functional tests for handling edge cases and other behavioral tests.
Outreach
- Writing blog post sharing my progress and GSoC experience along the way
- Opening up FTO's for new contributors and help review any pull requests.
- Improve Documentation, making them beginner friendly so as to make new contributors feel more guided through them.
Contributions
I have been an active contributor throughout the Public Lab ecosystem of repositories - with significant contributions to Public Lab's Image Sequencer and Plots2. Not only contributing with code and pull requests but being an active member by reviewing PRs, helping other fellow contributors, engaging in discussions and such. I am also part of the Image Sequencer CLI maintainers team and am working on the new test suite for sequencer CLI.
Experience
I feel very passionate about developing software and automating things. I feel very happy when my software helps people out and make their lives easier and more fun!
I primarily program in JavaScript and Go but not limited by them. I have worked on projects in various languages including Python, Ruby, Rust and C++.
Some of my notable projects are:
- Needzo - https://devpost.com/software/needzo | Auth0 Hackathon (Fifth-Community)
Needzo lets those under self-isolation and other vulnerable groups request deliveries and allows local volunteers to sort through, claim, and complete those deliveries with a gamified approach. - EndangAR - https://devfolio.co/submissions/endangar-bfce | Bitbox Winner - EchoAR Showcase We wanted to spread and create more empathy and knowledge towards the environment and wildlife out there. EndangAR is our project through which we spread awareness of endangered flora and fauna through an interactive map interface and rendering plant and animal models in 3D as well as Augmented Reality
- Bikeshed - https://github.com/daemon1024/bikeshed
A friendly neighborhood GitHub bot which automates trivial tasks for an organization and aims to provides a welcoming environment for newcomers. - Bolt262 - https://github.com/daemon1024/bolt262
It is CLI utility to run test262 tests for various hosts ( currently tested with node ). It currently aims to be as fast as possible and optimizations wherever possible. - TabuRei - https://github.com/daemon1024/TabuRei
TabuRei is an all-in-one browser extension to manage and store your tab clutter and restore them on the fly. It is fully Open-Source, and loaded with features. Try it at https://addons.mozilla.org/en-US/firefox/addon/taburei/
I take workshops and talks to bridge the gap between newcomers and development and spread awareness for FOSS at Open Source Developers Community(OSDC). Some of the projects I have collaborated at OSDC :
- Community Tools API OSDC - https://github.com/osdc/ct-api Proposed and Working on the automation of organizing meetups and notifying the attendees for OSDC.
- OSDC Bots - https://github.com/osdc/bots/commits?author=daemon1024 Maintaining and Contributing various fun and automation features to the community bots available for discord and telegram.
Other open source contributions:
- Add remove-members helper tool implemented in go - https://github.com/kubernetes/org/pull/2575
- Implement getting resource list for a service - https://github.com/keptn/keptn/pull/3232
- Consistently note in algorithms wherever steps may be inserted/modified elsewhere - https://github.com/tc39/ecma262/pull/2196
- Make Pycon India 2020 site responsive - https://github.com/pythonindia/inpycon2020/pull/78
- Add graphiql create-react-app example - https://github.com/graphql/graphiql/pull/1510
- Fix confusing error message in fs.utils - https://github.com/nodejs/node/pull/32896
- Handle detached arrays in XRView - https://github.com/servo/servo/pull/26185
Teamwork
I have participated in various hackathons and collaboratively made solutions to various societal problems with teams of 3/4 and have accomplishments in many of them. I volunteer at OSDC and we conduct meetups and events as well as work on projects with the entire community and thus, know how to work in a community. I am a firm believer of collaborative development and working with communities which is visible through most of my open source contributions.
Passion
I have been involved with Public Lab for quite a while now, and I started contributing because how caring and progressive the community was and I am really passionate about giving back to the community and continuing as well as improving this welcoming environment in the future.
Audience
This project aims to ease the process of adding interactive statistical map layers for volunteers and scientists which in-turn will help them display there research in much more intuitive manner. It will also attract developers and contributors who can leverage the LEL ecosystem. With additional optimized content on the /map page, it will improve the discoverability of research notes and community projects, bringing the Public Lab community closer and more interactive.
Commitment
There is no conflict of interest in coding phase as of now and I don't plan to have any other commitment during the period. If there will be any sudden changes in university schedule, I will discuss with the mentors.
I'd like to mention that I will, as I have done previously, continue to actively interact with the newer contributors and provide insight and any help that I can regarding their PRs and issues during (and after) my GSoC period. Hence, I firmly believe that I will deliver my assignments with commitment and promptness.
I look forward to working with the awesome community of Public Lab for a long time!
Needs
Help and guidance of my mentors as well as coordination from other contributors is all I need.
13 Comments
Hey @warren, @cess and all community members, Here is my draft proposal for the Geographic Features Refinement project. I am still working and detailing out the implementations as I gain deeper understanding of the project. All of your feedback and review are most welcome. Thank You 😃
Reply to this comment...
Log in to comment
Hi @barun1024, thanks so much for sharing your ideas. I like the extra explanations you have added for each item. I have a couple of questions/feedback:
You have a section called other refinements since they are part of the project, I would recommend expounding further on them as you have in the other features.
I did not see these two features mentioned in the proposal: Develop ideas and prototypes for how to ensure “important” or expected content is surfaced and Ranking by recency, views - brainstorm with community reps
What are some of the tests you will include in the project? Unit, functional, system.
Are there any accessibility features you can think about in the project?
Any plans to make First Timer Issues as you work on your project? We appreciate issues that invite newcomers to Public Lab.
Thanks again for your contributions to Public Lab and it's amazing to see the work you have done in the Open Source community.
Is this a question? Click here to post it to the Questions page.
Thanks @ruthnwaiganjo for the feedback 😃
I have added some details to them while I am working on expanding each of them further :)
I believe they are part of the same feature-set i.e.
ranking important/expected content based on various filters like views,recency. I have currently included under details of microservice. I believe it would be something similar to how sorting works in current search api( Ref. Let me know if I didn't get it right and point me towards the correct direction :)I plan to add all unit, functional and integration tests, since we need them all for all 'units' to work cohesively. I will be adding unit tests after completing each unit/functions. For integration tests, I prefer the top-down approach and testing each unit integration step by step and expanding. Functional tests for handling edge cases and other behavioral tests. I am open to other recommendations.
I will try to remain conformant with https://www.w3.org/WAI/test-evaluate/. Any further pointers appreciated.
Definitely. This initiative really helped getting started with open source and with public lab, so I am very eager in continuing it.
Is this a question? Click here to post it to the Questions page.
Reply to this comment...
Log in to comment
Hi Barun! Thanks so much for this proposal, it looks great. Some thoughts I wanted to share:
Regarding the micro-service idea, i'm curious what shortcuts we can take. I can imagine that this is relatively simple for a micro service. But, it's good to think about -- are there microservice templates or infrastructures we could build on to reduce the amount of code or infrastructure we'd need to build ourselves? Are there even websites out there that can be set up to scrape for us? Or, would it be possible to write the scraping script, but to have it dump into an existing geoJSON service and rely on their code's query optimization? I think there could be many different answers to this and I don't think we have to immediately know the best answer, but perhaps it's worth researching a bit to see what's out there and what the possibilities are.
Thanks so much Barun!!! 🎉
Is this a question? Click here to post it to the Questions page.
Hi @warren,
So the primary way of this whole workflow is everything is automated. What happens when you click the submit button is that, it will call the
github apiand open up an issue for us based on the form data, the community volunteer wouldn't need to do anything, just observe some ticks and maybe animations going 👀. We may need some bot account, saypubliclab-botfor this. In case this fails, we can display your suggestionthis sounds great.
Update:
I have attached an updated workflow which may better explain it.
P.s. Thanks a lot for the review, glad you liked it :)
Is this a question? Click here to post it to the Questions page.
Adding a gitpod integration to checkout the layer sounds great. Or we may choose to deploy it using gh pages like this https://publiclab.github.io/leaflet-environmental-layers/example and share that link instead. ( We may need to dabble into how to serve it with the build files from the PR ).
Generating independent files/code for anyone to add a specific layer to any map sound so cool.
agreed.
Has there been any existing layer, not necessarily spreadsheet based, being served as an independent file? If not I will try to experiment with some existing layers and see what exactly would we need to generate an independent code. I will open up an discussion thread on LEL repo for this if that sound right to you!
Update: I have included some details about this in my proposal now
Is this a question? Click here to post it to the Questions page.
Reply to this comment...
Log in to comment
One way would be to schedule cron jobs for scraping and dumping data and leverage a microservice to serve that data. We can use
github-actionto schedule this too. RefI am not exactly sure what do we want to
scrape, since we already have anapifor people and posts, hence I used the termcacheto as to reduce the load on theapi. Do we plan to use some external website which we would need to scrape for data?Is this a question? Click here to post it to the Questions page.
I think there are a few options on this. But the main thing is that we are making arbitrary bbox (bounding box) queries to an API using 2 latitudes and 2 longitudes, so a URL-based caching system probably won't work well, since people will zoom and drag the map in unpredictable ways.
However, the results are JSON, so we might think about how to store JSON objects in a geographic index for fast retrieval. Our database is actually not set up for that, as we use the more general purpose tags "lat:" and "lon:" and so we can't do as efficient database indexing on those.
https://publiclab.org/api/srch/taglocations?nwlat=47.15984001304432&selat=34.19817309627726&nwlng=-80.79345703125001&selng=-61.19384765625001
this is the query we get when we go to https://publiclab.org/map#6/41/-71, for example. Learn about this kind of API query here: https://publiclab.org/wiki/api
So I think we can think about 2 components - the "storage/retrieval" using a query /like/ the one above, and the mechanism to "scrape and store" from the PL API into that storage system.
For storage/retrieval, there seem to be many good options, i'm thinking node.js for lightweight and fast, but we can be flexible: https://duckduckgo.com/?q=efficient+nodejs+geojson+database&atb=v121-6&ia=web
For the scraping, I'm not sure. Maybe we could think about whether we are constantly scanning by region, or if accessing the microservice triggers a deferred re-fetch from the original API? These are really good design/architecture questions to weigh pros/cons on.
Thanks @barun1024!!!
Is this a question? Click here to post it to the Questions page.
That clarifies things a lots.
I understand the main issue is that we don't have an efficient database setup for geographic data.
I came across PostGIS which is a spatial database extender for PostgreSQL. Or we can extend our existing database since MySQL supports spatial data types (https://dev.mysql.com/doc/refman/8.0/en/spatial-types.html), we will have to way in pros and cons here.
Using a specialized database solves many of our problems like, - Indexing, https://postgis.net/workshops/postgis-intro/indexing.html most of these databases have an efficient spatial indexing already in place - Boundary Box Queries, https://postgis.net/docs/ST_Within.html and https://postgis.net/docs/ST_Contains.html are specialized geometry based queries ( boundary box in our case ) which have indexing automatically ( unless we specify other wise )
As you mentioned, Node.Js can be used for providing the interface on top of the database and greatly comfortable with the stack.
As for scraping and storing the data, We can provide some endpoint like
/create-map-data- which serves the purpose of providing interface for storing data directly into this database whenever a relevant node is created. As you already mentioned we will have to weigh in the pros/cons here.cc @warren
Hi Barun - thank you, that's good research. I'm quite in favor of an external stand-alone solution which doesn't add complexity to the plots2 database, esp because many spatial extensions are database specific, and wouldn't work with mysql, sqlite, etc -- I've definitely been down that road before and it is complicated. I am not 100% against it but my preference is to look at option which read in data via a standard access format like JSON (which is already available in plots2) and then create and maintain a self-contained efficient geodata store with premade indexing. I also like that this could involve a ready-to-use solution for storage, and that we might simply write the import script and run it periodically as a job.
My sense of cons on database extensions is that they place a lot of narrower requirements on our database choices in plots2, and the extra processing of populating and maintaining the tables is something we could bypass by externalizing. Does this make sense? Thank you!!!!
Is this a question? Click here to post it to the Questions page.
Reply to this comment...
Log in to comment
Thanks for addressing the feedback @barun1024, I would suggest updating your proposal using the feedback points shared to make it more comprehensive.
Thanks @ruthnwaiganjo , I have updated my proposal to include various feedbacks and improved upon it. I would really appreciate further feedback and suggestions :) Thanks Again 🎉
Reply to this comment...
Log in to comment
Login to comment.